
ABSTRACT
In the recent decade machine learning has become an integral part of the system, they can process and analyze large amounts of data in a matter of minutes which will take an eternity for humans. The compilation of data is so efficient and accurate that they have become an integral part of the whole ecosystem. No one can deny the fact that these techniques will be used in the future days more extensively and in every field, where large data would be needed. But this all sometimes came along with a very big compromise, the big data contained many documents that were private in origin and required freedom of interference due to its sensitive nature. So privacy came along like a big boulder to be moved ahead in the race for an unarguable interface with zero flaws. For which the big player may never worry anymore about their data being digested in between the third party during compilation.
SOLUTION-ORIENTED RESEARCH THAT SOLVES THE ISSUE
Many researchers came up together from universities across the world (Manipal institute of technology, Carnegie Mellon University, and Yildiz technical university) developed privacy-enabled models for analyzing and classifying financial texts. The made-up model was based upon the work of the predecessor paper that was published in arXiv, was based on the platform of machine learning and natural language processing techniques.
The uniqueness of this model was its approach that was strictly based on keeping the privacy of the users intact. One of their researchers spoke to the media that this work was based on their previous model namely (Benchmarking differential privacy and federated learning for BERT models). The model was an amalgamation of NLP (natural language processing) and privacy-enabled machine learning.
This combined effort of multiple domain inclusion had a simple main objective to fulfill that the privacy of the users will be well protected during the processing of the data. For example, the income tax filing, bank statement analysis, and real estate sales and purchases, documents like this have sensitive data that should not be leaked.
Machine learning that gives data-based insights and predicts based on the raw data it has been given, it becomes very hard for the code to realize which data is of sensitive origin and should be preserved simultaneously.
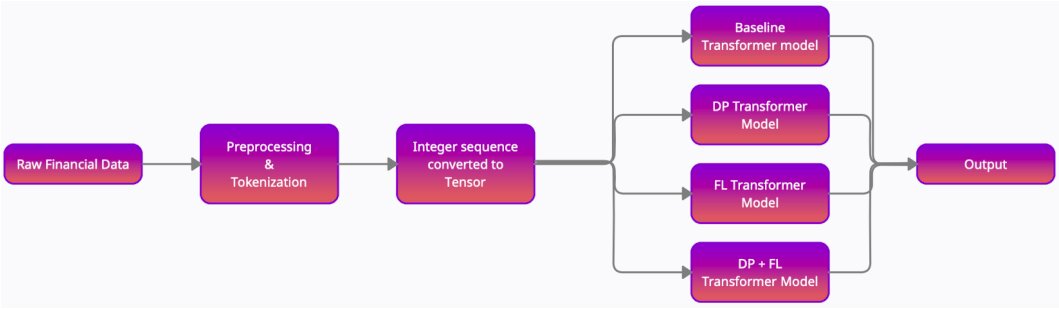
The financial model developed by the team is split into two approaches namely differential privacy and federated learning, finally combining these two components with BERT. As for BERT which is a renowned encoding model with past success fits perfectly with the system, just with some tweaks.
Differential privacy technique preserves privacy by adding different types of noises in the data that are of sensitive origin and needed to be preserved from the coders or developers. This results in the party abstaining from the specific data during processing.
And for federated learning method is a step-by-step utilization and processing of data whose main principle is the fragmentation of the data, this means no one has the total amount of data in a single point of time. Regarding BERT the researcher speaks that “BERT is a language model that gives contextualized embedding for natural language text which can be used later on multiple tasks, such as classification, sequence tagging, semantic analysis, etc.”
Based on all the pre-thought techniques and patterns the researchers used to train their NPL model system for classifying financial texts. After the training, the made system was extensively used to run backlogs with the financial data of different banks in its pre-written codes. The following experiment was a success.
This financial model will be used in many financial selections apart from that it will also be useful in other fields. To classify data the current approach will work as an appropriate tool without any compromise on private data breaches.
REFERENCES














